AI VIDEO BRIEFING
현대 LLM 아키텍처 비교 가이드 — GQA·MLA·슬라이딩 윈도우로 보는 트랜스포머 모델 50선
세바스찬 라쉬카가 직접 손으로 그린 50여 개 LLM 구조를 한곳에 모은 아키텍처 갤러리를 소개한다. KV 캐시를 줄이는 GQA·MLA·슬라이딩 윈도우·하이브리드 구조의 차이를 한국 독자 눈높이로 풀어 설명한다.
핵심 메시지
쉽게 이해하기
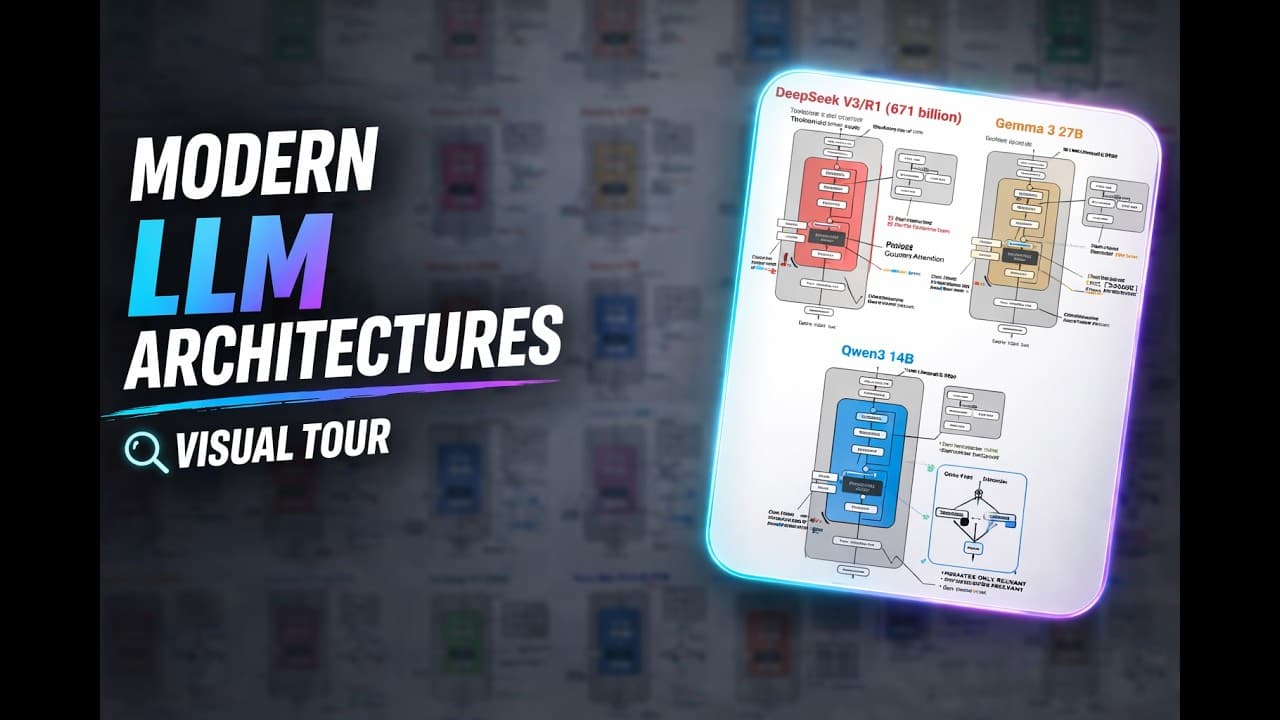
머신러닝 교육자 세바스찬 라쉬카는 지난 1~2년간 자신의 글과 게시물에서 다룬 50여 개의 대형언어모델(LLM) 구조를 한 페이지에 모은 ‘아키텍처 갤러리’를 만들었다. 각 모델의 그림은 자동화 도구가 아니라 그가 설정 파일과 기술 보고서, 실제 코드를 직접 읽고 손으로 그린 것이다.
갤러리에서는 어텐션 방식, 문맥 길이, 라이선스 같은 정보를 펼쳐 볼 수 있고, 두 모델을 골라 나란히 비교하면 무엇이 같고 무엇이 다른지 보여 준다. 예컨대 딥시크 v3와 v3.2는 거의 같지만 후자가 희소 어텐션을 추가했다는 식이다.
그가 강조하는 핵심은 최근 모델들이 GPT-2에서 파생된 비슷한 트랜스포머라는 점이다. 진짜 차이는 추론 시 메모리를 잡아먹는 KV 캐시를 줄이려는 여러 어텐션 변형에서 나타난다. 키·값을 공유하는 그룹 쿼리 어텐션(GQA), 키·값을 압축해 저장하는 다중 헤드 잠재 어텐션(MLA)이 대표적이다.
보는 범위 자체를 줄이는 방법도 있다. 슬라이딩 윈도우 어텐션은 과거 일정 구간만 보게 하고, 젬마는 다섯 개의 윈도우 계층마다 한 번씩 전체를 보는 5:1 구성을 쓴다. 딥시크 희소 어텐션은 여기서 한발 더 나아가 어떤 과거 토큰을 볼지 학습으로 고른다.
최근에는 일반 어텐션 대신 선형 어텐션이나 맘바 계열 상태공간 계층을 섞는 하이브리드 구조가 늘고 있다. Qwen3-Next가 대표적이며, 엔비디아 네모트론 나노는 맘바 계층을 많이 넣어 최대 100만 토큰 문맥을 합리적인 비용으로 지원한다.
주요 인사이트
- 모델 성능을 좌우하는 ‘비밀’보다, 같은 트랜스포머를 더 싸게 굴리려는 메모리 절약 기법들이 최근 구조 경쟁의 실제 무대다.
- GQA는 구현이 간단하지만 MLA가 같은 압축률에서 성능을 더 잘 보존한다. 다만 MLA는 학습 튜닝이 까다로워 보통 큰 모델에서야 이점이 뚜렷해진다.
- 인도의 모델이 30B에는 GQA를, 105B에는 MLA를 쓴 사례처럼, 어텐션 선택은 모델 크기에 맞춰 의도적으로 조정되는 하이퍼파라미터다.
- 에이전트형 응용이 늘며 문맥이 길어지자 KV 캐시 절감이 구조 설계의 일순위 동기가 됐다.
- 흩어져 있던 정보를 한 갤러리에 모아 비교 가능하게 만든 것 자체가, 빠르게 쏟아지는 모델들을 따라잡는 실용적 학습 도구가 된다.
자주 묻는 질문
그룹 쿼리 어텐션(GQA)은 무엇을 절약하나요?
여러 쿼리가 같은 키·값을 공유하게 해서 캐시에 저장할 키·값의 수를 줄입니다. 공유 그룹이 많을수록 KV 캐시가 작아지지만, 너무 줄이면 성능이 떨어질 수 있어 적절한 비율을 찾아야 합니다.
다중 헤드 잠재 어텐션(MLA)은 GQA와 어떻게 다른가요?
MLA는 키·값을 그대로 공유하는 대신 압축된 잠재 표현으로 줄여 저장했다가 사용할 때 다시 펼칩니다. 딥시크의 실험에 따르면 같은 압축률에서 GQA보다 성능 저하가 적지만 구현과 학습이 더 까다롭습니다.
슬라이딩 윈도우 어텐션은 왜 쓰나요?
각 토큰이 볼 수 있는 과거 토큰 범위를 일정 폭으로 제한해, 더 오래된 키·값을 캐시에서 비울 수 있게 합니다. 젬마는 중요한 정보를 놓치지 않도록 일정 간격마다 전체를 보는 계층을 끼워 5:1 비율로 사용합니다.
원문과 출처
이 글은 원본 영상의 자막을 바탕으로 한국어 독자를 위해 요약했습니다. 전체 맥락과 최신 정보는 원문에서 확인하세요.
YouTube 원본 영상 보기 ↗