AI VIDEO BRIEFING
ELECTRA 사전학습 원리 정리: BERT보다 4배 효율적인 토큰 판별 방식의 비밀
ELECTRA는 마스킹된 토큰을 맞히는 대신 모든 토큰이 진짜인지 가짜인지 판별하게 해 BERT 대비 학습 연산을 약 4배 줄인다. 생성기와 판별기가 협력하는 구조, 효율 향상의 진짜 원인, 그리고 한계까지 정리했다.
핵심 메시지
쉽게 이해하기
대규모 언어 모델이 커질수록 사전학습 비용이 중요한 문제가 된다. ELECTRA는 BERT 계열의 사전학습을 더 싸게 하려는 방법으로, 같은 성능에 이르는 데 드는 연산량(FLOPs)을 약 4배 줄인다고 주장한다. 모델과 코드가 허깅페이스에 공개돼 있어 실무 적용을 고려할 만한 기법이다.
BERT는 트랜스포머 기반의 양방향 인코더로, 텍스트를 워드피스 토크나이저로 잘라 숫자로 바꾸고 임베딩과 위치 인코딩을 더한 뒤 트랜스포머 층을 쌓는다. 핵심은 비지도 사전학습인데, 입력의 약 15%를 무작위로 가린 뒤 모델이 가려진 자리에 무엇이 있었는지 맞히게 한다. 문제는 이 방식이 전체의 15%에서만 학습 신호를 얻어 매 스텝의 계산을 충분히 활용하지 못한다는 점이다.
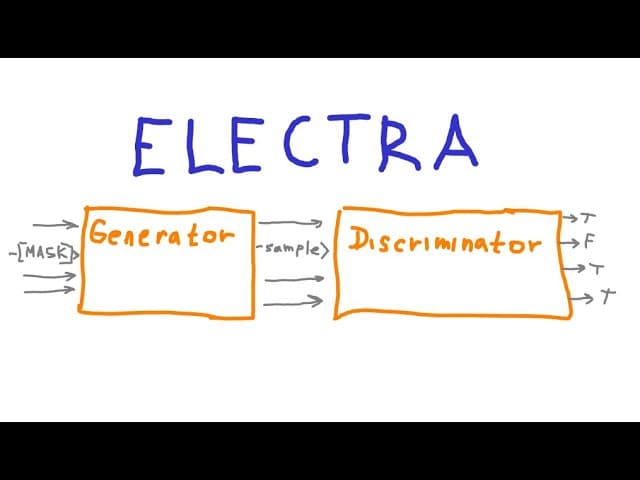
ELECTRA의 아이디어는 모든 위치에서 무언가를 배우게 만드는 것이다. 먼저 작은 생성기가 기존처럼 마스크 자리를 자기 추측으로 채운다. 그다음 더 큰 판별기가 생성기의 출력과 원본 토큰을 받아, 각 위치의 토큰이 원래 것인지 아니면 교체된 것인지를 판별한다. 이렇게 하면 일부가 아니라 입력의 모든 토큰에서 학습 신호가 생긴다.
구조적으로 생성기와 판별기는 같은 형태지만 임베딩과 위치 인코딩만 공유한다. 생성기는 판별기보다 작아야 좋은데(보통 4분의 1~2분의 1), 너무 크면 교체된 토큰을 가려내기가 지나치게 어려워져 판별기가 유용한 것을 배우지 못한다. 두 모델은 함께 학습되며 전체 손실은 생성기의 언어모델링 손실과 판별기의 판별 손실의 합이다. 다만 이것은 GAN이 아니다. 생성기는 판별기를 속이려는 것이 아니라 자기 과제를 풀 뿐이다.
결과적으로 ELECTRA는 RoBERTa와 비슷한 GLUE·SQuAD 성능을 약 4배 적은 학습 연산으로 달성한다. 저자들이 과제를 단계적으로 바꿔 가며 분석한 결과, 향상의 핵심은 '판별'이라는 형식 자체보다 '모든 입력 토큰에서 손실이 발생한다'는 점이었다. 학습이 끝나면 생성기는 도구로 쓰고 버린 뒤 판별기만 최종 모델로 남긴다. 이후 대조 학습을 접목하거나 더 많은 층을 공유하려는 후속 연구들도 이어졌다.
주요 인사이트
- 향상의 진짜 원천은 판별이라는 형식이 아니라 '모든 토큰에서 손실이 발생한다'는 점이다. 마스크 언어모델링을 15%가 아닌 전체 토큰으로 확장하면 ELECTRA에 근접한 결과가 나온다.
- ELECTRA는 GAN처럼 보이지만 GAN이 아니다. 생성기는 판별기를 속이도록 적대적으로 학습되지 않고, 가려진 자리를 복원하는 자기 과제만 수행한다.
- 생성기를 무작정 키우면 역효과가 난다. 생성기가 너무 강하면 만들어 내는 교체 토큰이 너무 그럴듯해져, 판별기가 진짜와 가짜를 구분하며 배울 신호가 사라진다.
- 최종 산출물은 판별기 하나뿐이다. 생성기는 학습 과정에서 어려운 사례를 만들어 주는 보조 도구이며 추론 단계에서는 사용하지 않는다.
- ELECTRA는 수렴이 빠른 만큼 데이터가 적은 저자원 환경에서도 유리할 가능성이 있다. 이는 영상에서 제시된 추측으로, 확정된 결론은 아니다.
자주 묻는 질문
ELECTRA가 BERT보다 효율적인 근본 이유는 무엇인가요?
BERT는 가려진 약 15%의 토큰에서만 학습 신호를 얻지만, ELECTRA는 판별기가 입력의 모든 토큰이 원본인지 교체됐는지를 판단하게 해 전체 토큰에서 손실이 발생합니다. 분석 결과 이 '모든 토큰에서의 학습'이 효율 향상의 핵심으로 나타났습니다.
ELECTRA는 GAN과 같은 방식인가요?
아닙니다. 생성기와 판별기가 등장하지만, 생성기는 판별기를 속이려고 적대적으로 학습되지 않고 가려진 토큰을 복원하는 자기 과제만 풉니다. 두 모델은 함께 학습되지만 목표가 서로 대립하지 않습니다.
학습이 끝나면 생성기는 어떻게 되나요?
버립니다. 생성기는 학습 중 교체 토큰을 만들어 주는 보조 도구일 뿐이며, 학습이 끝나면 우리가 실제로 원하는 큰 모델인 판별기만 남겨 다운스트림 과제에 사용합니다.
원문과 출처
이 글은 원본 영상의 자막을 바탕으로 한국어 독자를 위해 요약했습니다. 전체 맥락과 최신 정보는 원문에서 확인하세요.
YouTube 원본 영상 보기 ↗