AI VIDEO BRIEFING
머신러닝 입문 쉽게 이해하기: 예측·분류 개념과 테스트 데이터로 좋은 모델 고르는 법까지
조시 스타머의 스탯퀘스트 머신러닝 입문 강의를 정리했습니다. 결정 트리와 직선·곡선 예시로 예측·분류 개념을 설명하고, 훈련 데이터가 아닌 테스트 데이터로 좋은 모델을 고르는 핵심 원리를 쉽게 짚어 줍니다.
핵심 메시지
쉽게 이해하기
강사 조시 스타머는 "스탯퀘스트를 좋아할 사람인가"를 맞히는 익살스러운 예시로 결정 트리를 소개한다. 익살스러운 노래·머신러닝·통계에 대한 관심을 차례로 묻는 질문들로 가지를 따라 내려가 사람을 분류하는데, 이 결정 트리 자체가 간단한 머신러닝 방법이다. 트리로 어떻게 예측·분류하는지 이해하면 머신러닝의 큰 줄기를 잡은 셈이라고 말한다.
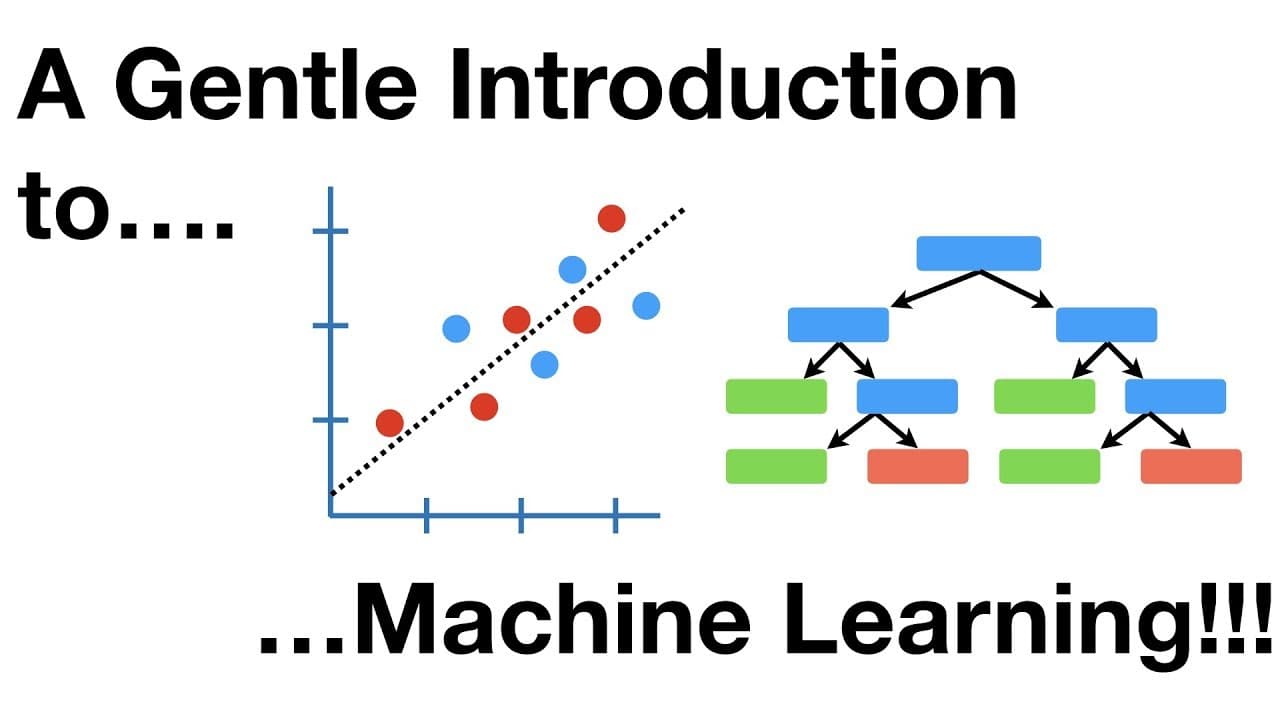
두 번째 예시는 "얌(yam)을 많이 먹을수록 100m를 빨리 달린다"는 가상의 데이터다. 데이터에 검은 직선을 맞추면 추세가 보이고, 누군가 얌을 얼마나 먹었는지 알려 주면 그 직선으로 달리기 속도를 예측할 수 있다. 강사는 이처럼 머신러닝이 본질적으로 예측과 분류를 하는 일이라고 정리한다.
핵심은 모델을 어떻게 고르느냐다. 원래 데이터(훈련 데이터)에 검은 직선 대신 구불구불한 초록 곡선을 맞출 수도 있다. 초록 곡선은 훈련 데이터를 더 잘 맞추지만, 목표는 예측이므로 새로 모은 테스트 데이터로 둘을 비교해야 한다. 각 사람의 실제 속도와 예측 속도의 거리를 모두 더해 보면, 곡선이 훈련 데이터를 더 잘 맞췄어도 직선의 오차 합이 더 작다. 따라서 예측에는 직선을 택한다.
이 예시는 두 가지를 가르친다. 첫째, 머신러닝 방법은 테스트 데이터로 평가한다. 둘째, 훈련 데이터에 얼마나 잘 맞는지에 속지 말아야 한다. 강사는 훈련 데이터에는 잘 맞지만 예측은 나쁜 이런 상황을 편향-분산 트레이드오프라고 부른다. 또한 굳이 화려한 딥러닝 합성곱 신경망을 쓰지 않고 단순한 직선·곡선을 쓴 이유로, 무엇을 쓰든 가장 중요한 것은 화려함이 아니라 테스트 데이터에서의 성능임을 강조한다.
마지막으로 처음의 결정 트리로 돌아간다. 스탯퀘스트를 좋아하는 사람과 아닌 사람의 데이터를 모아 훈련 데이터로 트리를 만들고, 또 다른 사람들의 데이터를 테스트 데이터로 삼아 트리의 예측을 실제와 비교한다. 같은 방식으로 다른 최신 방법과도 견줘 가장 잘 맞히는 방법을 고른다. 어떤 데이터를 훈련용·테스트용으로 나눌지에도 정해진 방법들이 있다고 덧붙인다.
주요 인사이트
- 머신러닝을 거창하게 보지 말고 "예측과 분류"라는 한 문장으로 잡으면 입문 장벽이 크게 낮아진다.
- 훈련 데이터 적합도와 예측 성능은 다르다. 훈련 데이터를 완벽히 맞추는 모델이 오히려 새 데이터에서 더 나쁠 수 있다.
- 모델 선택의 기준은 "테스트 데이터에서의 오차"다. 화려한 알고리즘이라도 이 기준을 통과하지 못하면 의미가 없다.
- 결정 트리처럼 단순한 방법도 예측·분류를 하면 엄연한 머신러닝이며, 개념 이해의 좋은 출발점이 된다.
- 훈련용·테스트용 데이터를 나누는 방식 자체도 성능에 영향을 주므로, 분할 방법을 고민하는 것이 중요하다.
자주 묻는 질문
머신러닝을 한마디로 정의하면 무엇인가요?
영상에서는 머신러닝을 "예측과 분류를 하는 일"로 정의합니다. 직선으로 속도를 예측하거나 결정 트리로 사람을 분류하는 것이 그 예입니다.
훈련 데이터에 잘 맞는 모델이 항상 좋은 모델인가요?
아닙니다. 구불구불한 곡선이 훈련 데이터를 더 잘 맞춰도, 테스트 데이터에서는 단순한 직선의 예측 오차가 더 작을 수 있습니다.
여러 머신러닝 방법 중 무엇을 쓸지 어떻게 정하나요?
별도로 모은 테스트 데이터에서 실제 값과 예측 값의 오차를 비교해, 예측을 더 잘하는 방법을 선택합니다.
편향-분산 트레이드오프는 무엇과 관련된 개념인가요?
영상에서는 훈련 데이터에는 잘 맞지만 예측은 나쁜 상황을 편향-분산 트레이드오프라고 부르며, 더 알고 싶으면 관련 스탯퀘스트를 보라고 안내합니다.
원문과 출처
이 글은 원본 영상의 자막을 바탕으로 한국어 독자를 위해 요약했습니다. 전체 맥락과 최신 정보는 원문에서 확인하세요.
YouTube 원본 영상 보기 ↗